はじめに
この記事ではUnity ML-Agentsのサンプルを触ってみます。
— YouTubeなら12分28秒で学べます ―
Unity ML-Agentsの準備
前回の記事
前回の記事を参照して、「6、Unity側のML-Agentsの設定」まで終わらせてください。今回もAnaconda Navigatorのコマンドプロンプトを使用します。
また、前回同様、開発環境はWindows 10 (64 bit)、Python 3.7 、Unity 2017.4.13f1、ML-Agents ver 0.5を想定しています。
「Basic」の概要
デフォルトで入っているサンプル、「Basic」は、1体のAgent(Cube)を操作してゴール(Sphere)まで導くエピソードを学習させる「Single-Agentシナリオ」です。
Agentとは、移動や回転といった、「行動」を起こす学習者のオブジェクトを指します。

「Basic」の準備
Unityを起動して、File > Open Projectより「UnitySDK」を開いてください。場所はml-agents-master/UnitySDKです。
前回の記事を読んで、ML-Agentsのインポートが完了しておりましたら、「ML-Agents」のフォルダがAsset内にあると思います。
ML-Agents/Examples/Basic/Scenes内の「Basic」を開いてください。
以下のような画面になります。
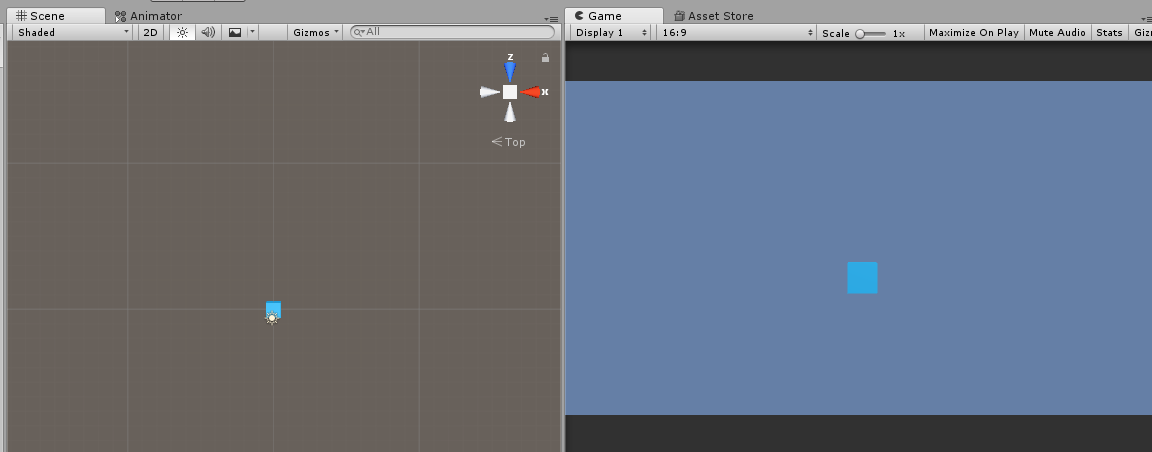
AgentをPlayerで操作してみる
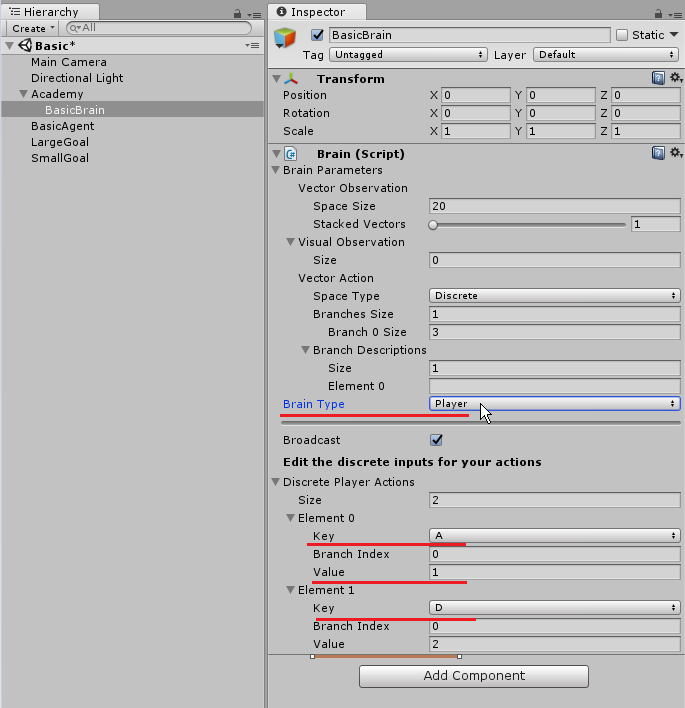
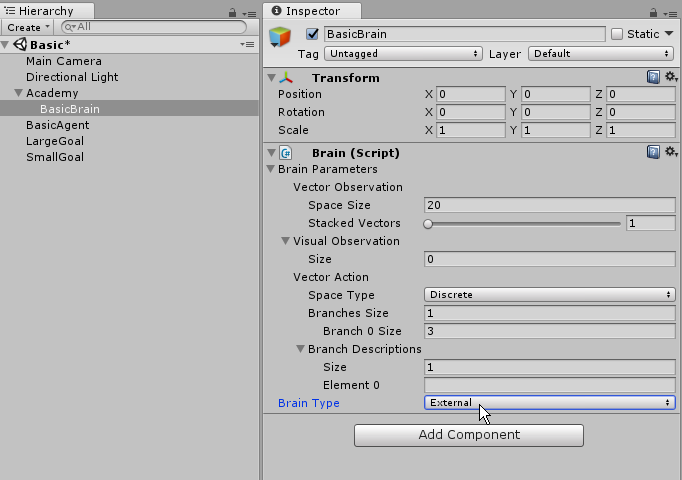
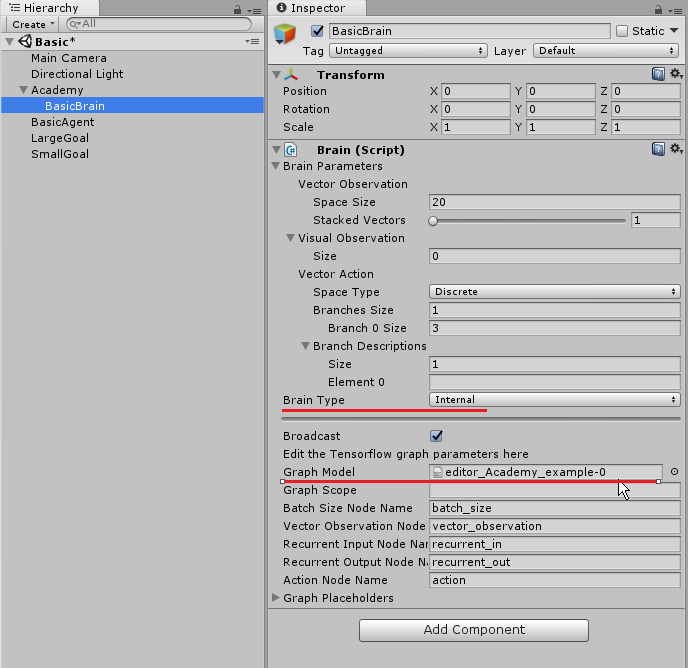
Hierarchyの「BasicBrain」のInspector内にBrainスクリプトがアタッチされています。
その中の「Brain Type」を「Player」にしてください。これで、人間の入力を使用した学習が行えます。
操作方法はKey Aで左に移動し、Key Dで右に移動です。また、Discreate Player Actions を見てもらったら分かるように、Key Aを押すとValue=1が返され、Key DでValue =2が返されます。
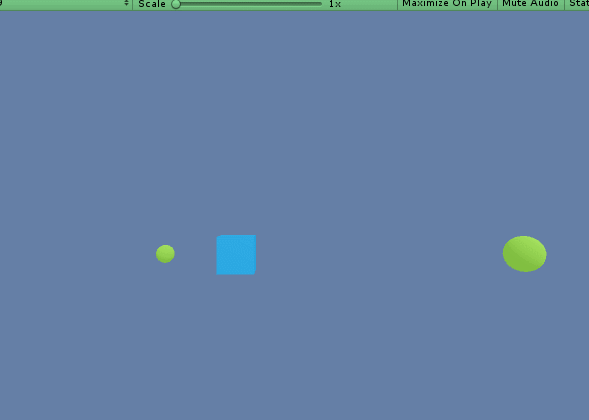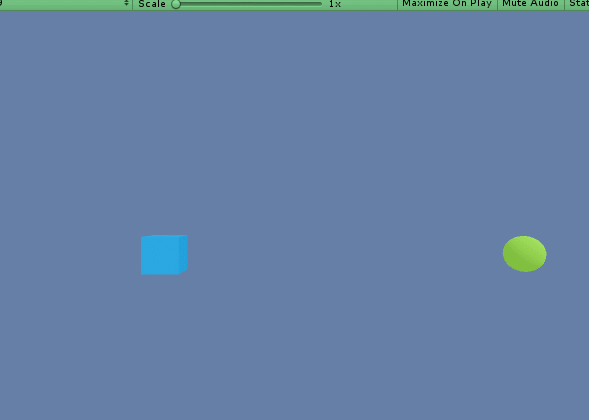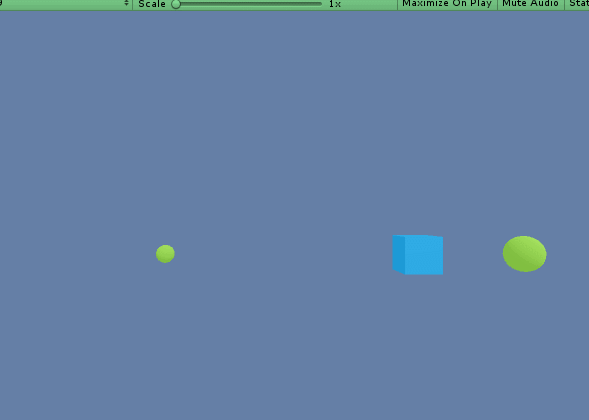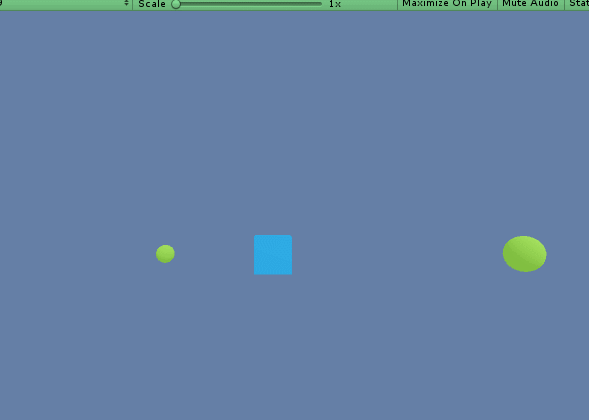
実行してAとDで移動し、緑のボールに当たるとゲームがリセットされます。この一連の動きを「エピソード」と呼び、これを学習させていきます。
TensorFlowを使用した機械学習
「BasicBrain」のBlain Typeを「External」に変更してください。これで、外部からTensorFlow(または自作のMLライブラリ)を使った学習が行えます。
ちなみに、Hierarchy内で重要なオブジェクトが3つあります。それは、「Brain」「Agent」「Academy」です。
学習の流れとしては、「Agent」が行った行動を「Brain」が記憶、計算し推論モデルを形成することで動きを決定していきます。こういった学習環境を管理する役割が「Academy」です。
ML-Agentsではこれら3つが必須となります。
続いて、Anaconda Navigator を起動して、コマンドプロンプトを開いてください。
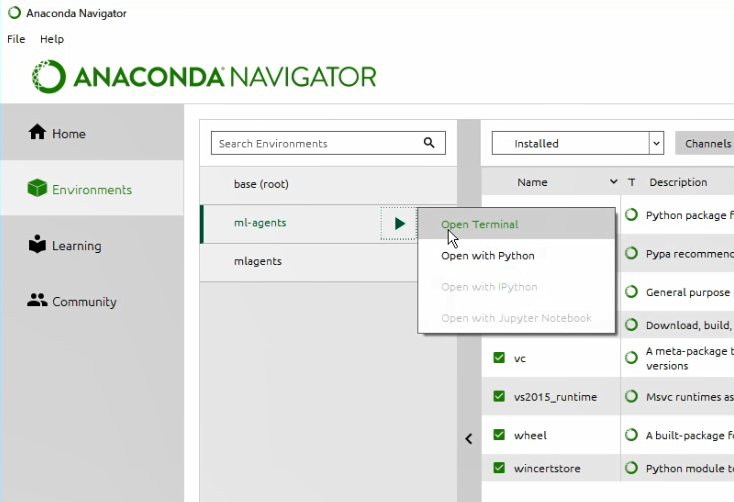
私の時は変更する必要はなかったですが、もし、各行の頭が(base)のようになっていたら、「activate ml-agents」と入力して実行し、(ml-agents)に変えてください。
![]()
続いて、コマンドプロンプトのディレクトリをml-agents-master/ml-agentsへ移動したいので、ml-agentsフォルダを開いて絶対パスをコピーしてください。
私の場合はml-agents-masterフォルダはデスクトップ上においてあります。ユーザー名などに日本語が入っている場合はエラーが出る場合がございますので、適宜移動させてください。
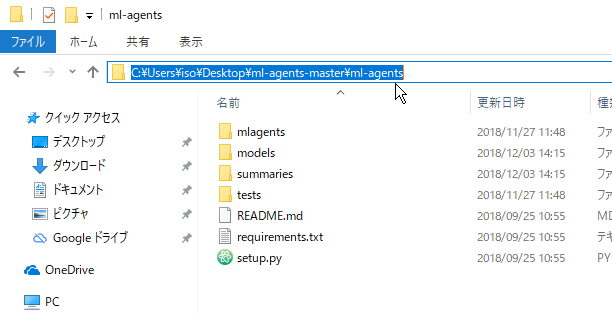
続いて、コマンドプロンプト上で「cd 絶対パス」のように入力してEnterを押して下さい。
|
1 2 3 |
コマンドプロンプト cd C:\Users\ユーザー名\Desktop\ml-agents-master\ml-agents |
続いて、「mlagents-learn ../config/trainer_config.yaml –run-id=実行結果を保存するフォルダ名 –train」のように入力してください。
|
1 2 3 |
コマンドプロンプト mlagents-learn ../config/trainer_config.yaml --run-id=example --train |
「mlagents-learn」は学習と推論の両方を設定できるスクリプトです。一つ前のバージョンv0.4 では「python3 learn.py」のように使用しておりましたが、v0.5で「mlagents-learn」に変更となりました。
「../」で ml-agentsフォルダの一つ上のフォルダに移動し、その中のconfigフォルダ内にある「trainer_config.yaml」を実行してくださいというコマンドになります。
trainer_config.yamlの中身は以下のように、機械学習に用いる様々なパラメータが入っています。
「–run-id=実行結果のファイル名」で学習後に生成されるフォルダ名を決定します。すでにその名前が使用されている場合は、同フォルダ内にファイルが生成されます。上書きはされません。
最後に、「–train」で学習を実行します。
trainer_config.yaml(一部抜粋)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
default: trainer: ppo batch_size: 1024 beta: 5.0e-3 buffer_size: 10240 epsilon: 0.2 gamma: 0.99 hidden_units: 128 lambd: 0.95 learning_rate: 3.0e-4 max_steps: 5.0e4 memory_size: 256 normalize: false num_epoch: 3 num_layers: 2 time_horizon: 64 sequence_length: 64 summary_freq: 1000 use_recurrent: false use_curiosity: false curiosity_strength: 0.01 curiosity_enc_size: 128 |
–train を実行すると以下のようなUnityのロゴと共に、一番下に「Start training by pressing the Play button in the Unity Editor」という文字が現れるので、Unity上でゲームを実行してください。
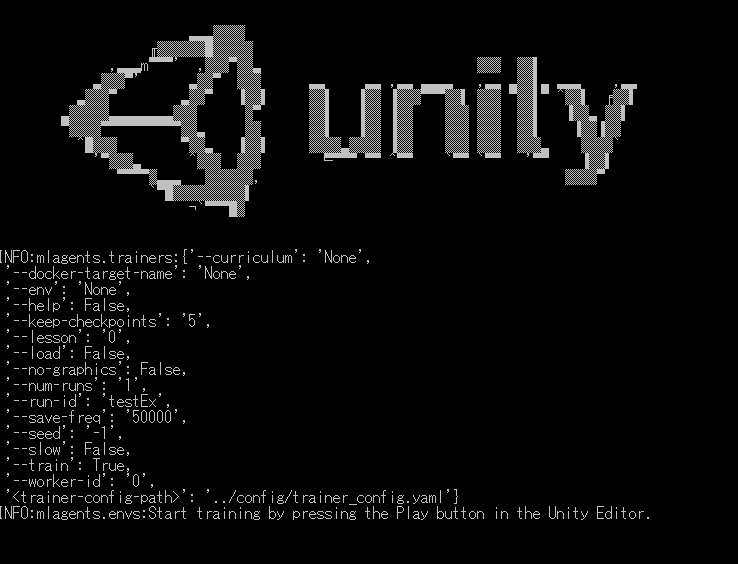
ゲームを実行すると、自動でAgentが動き出し、学習し始めます。
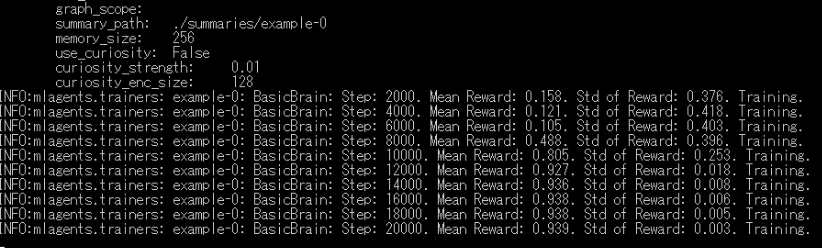
以下のように次々に文字や数字が流れていきます。
「Step」が移動などのActionを実行した回数、「Mean Reward」が平均報酬額、「Std of Rward」が報酬額の標準偏差になります。
今回の場合、小さいボールに到達したときが報酬「+0.1」、大きいボールに到達したときが「+1」になってます。
また、今回では1Stepごとに報酬「-0.01」となるので、最短距離で移動した方が高い報酬を得られる仕組みになってます。
Unity上でゲームを停止すると、学習も自動的に停止されます。
学習したデータは ml-agents-master/ml-agents/summaries内にあります。
先ほど学習したデータを確認する場合は、コマンドプロンプト上で「tensorboard –logdir=summaries」と入力してください。
|
1 2 3 |
コマンドプロンプト tensorboard --logdir=summaries |
すると、「http://○○:6006」のようなローカルホストのURLが生成されますので、これをブラウザに入力して移動してください。
これで、「TensorBoard」上で得られたデータをグラフ化してみることができます。
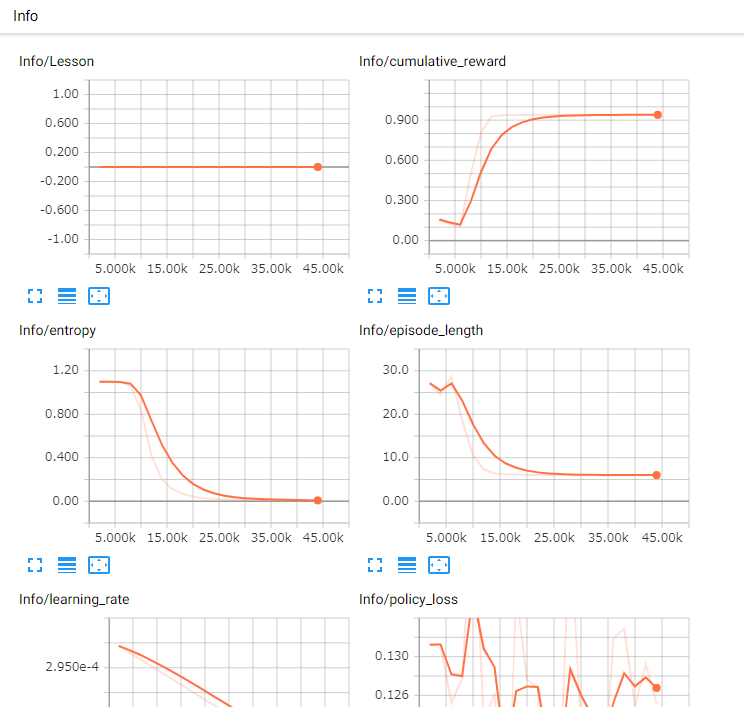
グラフの見方は以下のリンクを参考にしてください。
推論モデルをUnityで使用する
学習して得られた推論モデルは ml-Agents/models/自分で指定した名前のフォルダ内に入ってます。
「自分で指定した名前.bytes」ファイルをドラッグ&ドロップでUnityのAsset内にコピーしてください。

UnityのHierarchyのBasicBrainのBrainTypeを「Internal」に変更して、Graph Model に先ほどの.bytesファイルをドラッグ&ドロップしてください。
ゲームを実行すると、推論モデルを適用してAgentが動きます。
「Basic」のパラメータ設定
trainer_config.yaml(一部抜粋)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
default: trainer: ppo batch_size: 1024 beta: 5.0e-3 buffer_size: 10240 epsilon: 0.2 gamma: 0.99 hidden_units: 128 lambd: 0.95 learning_rate: 3.0e-4 max_steps: 5.0e4 memory_size: 256 normalize: false num_epoch: 3 num_layers: 2 time_horizon: 64 sequence_length: 64 summary_freq: 1000 use_recurrent: false use_curiosity: false curiosity_strength: 0.01 curiosity_enc_size: 128 BasicBrain: batch_size: 32 normalize: false num_layers: 1 hidden_units: 20 beta: 5.0e-3 gamma: 0.9 buffer_size: 256 max_steps: 5.0e5 summary_freq: 2000 time_horizon: 3 |
trainer_config.yamlではdefault のパラメータがあらかじめ表記されており、それを上書きする形でパラメータを変更します。
「Brain」では「Basic Brain」がそれにあたります。
batch_size: 32、buffer_size: 256
今回のActionは移動のみであり、値はx = 0, 1, 2…のように離散的です。
このように、整数のみを扱う「Discrete」の場合は小さな値を使用します。範囲はBatch_size(32~512)、Buffer_size(2048~409600)です。
なお、Buffer_sizeはBatch_sizeの倍数である必要があります。
nurmalize:false
Agentの行動により得られた値(Observation)を自動的に正規化するかどうかを指定します。今回はしないのでfalse。
num_layers:1
単純な問題の場合、レイヤーを少なくした方が学習効率が上がりやすく、複雑な問題の場合は多くのレイヤーが必要になる。レイヤー数の範囲は1~3層。
単純な系なので小さな値1を指定。
hidden_units: 20
Actionが簡単な場合は小さな値を使用します。範囲は(32 ~ 512)
beta: 5.0e-3
betaはエントロピーの正則化の強さを表しています。値を大きくするとBrainのActionのランダム性が増します。
エントロピーの減少が早すぎるときはbetaを増やす必要があります。範囲は0.01 ~ 10000です。
gamma: 0.9
gamma は報酬割引率を表しています。遠い将来のためにAgentが行動しているときは大きな値を使用します。範囲は0.8 ~ 0.995。
max_steps: 5.0e5
学習の最大ステップ数です。
summary_freq: 2000
学習した統計情報を保存する間隔です。今回は2000ステップで1回です。
time_horizon: 3
Agentごとに取集するデータのステップ数です。エピソード内で頻繁に報酬が与えられる場合は小さな値を使用。範囲は(64 ~ 2048)。
「Basic」のスクリプトの解説
Asset/ML-Agents/Example/Basic/Scripts内にある「BasicAgent.cs」に、Agentの行動や報酬を受け取る条件が記入されています。
コメントを付けておきましたので、興味のある方はご覧ください。
BasicAgent.cs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
using System.Collections; using System.Collections.Generic; using UnityEngine; using MLAgents; public class BasicAgent : Agent { [Header("Specific to Basic")] private BasicAcademy academy; public float timeBetweenDecisionsAtInference; private float timeSinceDecision; int position; int smallGoalPosition; int largeGoalPosition; public GameObject largeGoal; public GameObject smallGoal; int minPosition; int maxPosition; //Agent初期化時に呼び出し public override void InitializeAgent() { //BasicAcademyに一致するObjectを返す(Find系の中で一番処理が遅い) academy = FindObjectOfType(typeof(BasicAcademy)) as BasicAcademy; } //Stateの取得時に呼び出し(Agentの状態(位置など)が変化すると更新される) public override void CollectObservations() { AddVectorObs(position, 20); } //ステップごとに呼ばれる(Unityの1フレームごとに処理が実行される) public override void AgentAction(float[] vectorAction, string textAction) { var movement = (int)vectorAction[0]; int direction = 0; switch (movement) { case 1: direction = -1; break; case 2: direction = 1; break; } position += direction; if (position < minPosition) { position = minPosition; } if (position > maxPosition) { position = maxPosition; } gameObject.transform.position = new Vector3(position - 10f, 0f, 0f); //1ステップ毎の報酬 AddReward(-0.01f); //小ゴールへ到着 if (position == smallGoalPosition) { //エピソード完了と報酬の受け取り Done();//Reset On Doneにチェックが入っているときは即リセット AddReward(0.1f); } //大ゴールへ到着 if (position == largeGoalPosition) { Done(); AddReward(1f); } } //リセット時の処理 public override void AgentReset() { position = 10; minPosition = 0; maxPosition = 20; smallGoalPosition = 7; largeGoalPosition = 17; smallGoal.transform.position = new Vector3(smallGoalPosition - 10f, 0f, 0f); largeGoal.transform.position = new Vector3(largeGoalPosition - 10f, 0f, 0f); } //エピソード完了時に呼ばれるメソッド public override void AgentOnDone() { } //UnityのMonobehaviourのメソッド。固定フレームで呼び出す。 public void FixedUpdate() { WaitTimeInference(); } private void WaitTimeInference() { //現在の状態が学習か推論かの取得 //推論ではない場合=学習 if (!academy.GetIsInference()) { //On Demand Descisionsにチェックが入っているとき、RequestDecision()でActionを決定する RequestDecision(); } //推論の場合 else { //0.15秒ごとにActionを決定(timeBetweenDecisionsAtInferenceは0.15) if (timeSinceDecision >= timeBetweenDecisionsAtInference) { timeSinceDecision = 0f; RequestDecision(); } else { //timeSinceDecisionを固定時間で増加 timeSinceDecision += Time.fixedDeltaTime; } } } } |
